
What is the Modern Data Stack?
The Modern Data Stack is a popular approach to data integration and analytics that relies on multiple cloud tools to ingest data from a specific source, store your data in a data warehouse, and transform and analyze your data.
The limitations of the Modern Data Stack
As a revenue operations professional, you’re always on the lookout for opportunities to grow revenue and improve efficiency while keeping important revenue processes humming. However, the core of your processes–the disparate tools in your tech stack–may be costing you more than you think. Your organization has likely adopted some form of the Modern Data Stack. Your team may even be operationalizing your data via reverse ETL, the practice of flowing data out of your warehouse to other tools to better inform processes for specific teams.
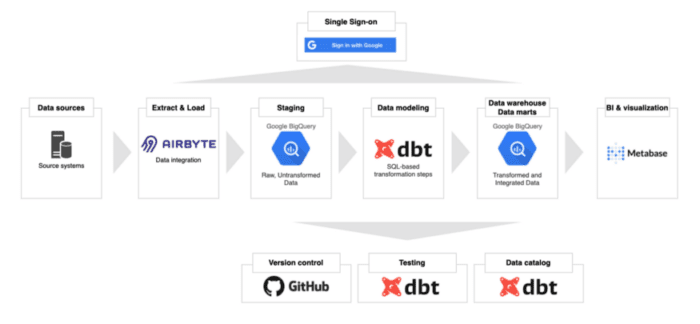
The Modern Data Stack includes a connector, a warehouse, data transformation, and analytics. Image courtesy Towards Data Science.
In theory, the Modern Data Stack was supposed to be the perfect answer to your company’s increasing influx of crucial lead and customer details, and the need to manage all that important data. In practice, the Modern Data Stack is becoming more unwieldy and difficult to manage. Reports show that marketing budgets are continuing to increase, with 2022 budgets being up to 9.5% of total company revenue. However, 26% of CMOs report capability gaps in data and analytics, and 22% of CMOs suggest gaps in managing MarTech overall. Essentially, revenue teams everywhere are bolting new technology onto their existing technology stack every year, but revenue leads remain skeptical of their value.
The problem is that the Modern Data Stack might have made sense years ago to primarily handle analytics for one dataset across a handful of tools. But RevOps teams like yours need more than just analytics on a single data stream–you need orchestration across a variety of different systems for mission-critical activities such as lead management and campaign execution. You also need comprehensive metrics across multiple tools to help you clearly and accurately visualize performance across the funnel, not just for yourself, but for other teams across your organization. The real issue, as you’ve known all along, is that the core of your most important work isn’t your tools at all–it’s your data.
The underlying RevOps challenge with the modern data stack is the data, not the tools
In modern RevOps, data is essential. In order to successfully manage lead flow and generate pipeline, your team collects more data than ever, including lead records, engagement, conversions, website performance, and much, much more. Now, more than ever, you need the ability to collect data from many different sources and use it to fuel everything you do.
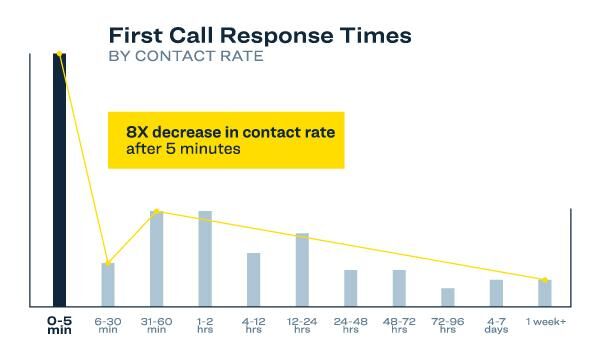
Siloed data means slower response times, which means lower response and conversion rates. Image courtesy InsideSales.
Unfortunately, if you’re relying on the Modern Data Stack model, it’s likely that you already struggle with data quality and reliability. As you attempt to manage processes across different applications, your most important data is siloed, locked up within one app or another. Each app only has a piece of the puzzle, and not all of them reflect recent updates or changes in process or technology. Without the ability to unify your most important data into a central working model that reliably reflects recent changes and delivers uniform, consistent results, you’ll never have full visibility into your funnel and performance at different stages. As a result, working with the Modern Data Stack means you’ll continue to struggle with these challenges:
Inability to diagnose or take action
Accurately diagnosing marketing performance continues to be a struggle for teams that need to work with data siloed across many apps. Not having full visibility into exactly what’s happening with leads and conversions means your team can’t properly diagnose performance challenges. Is the recent drop in top-of-funnel leads due to Google penalizing your website due to an algorithm change, increasing competitive pressure through organic channels, or something else? Without being able to reliably diagnose the breakdowns, you also don’t have a clear picture of what activities you should prioritize first to solve them.
Operational delays
As your data breaks down, you need to commit more of the limited hours in your day to chasing down bad data. As a result, you get stuck spending more time in the proverbial weeds, re-uploading failed intake jobs, enriching incomplete leads, de-duplicating dupe-filled records, or reconciling mismatched fields…while having less bandwidth for strategic projects.
Slower lead follow-up and lower conversions
With incomplete revenue data and operational setbacks come delays and confusion with routing and assigning leads to the correct sales representatives. The longer your reps are waiting on leads, the colder those leads become. Research suggests that 50% of all deals go to the vendor that follows up first. All the bad leads your team needs to triage means delays that put those leads in jeopardy of dying on the vine.
Reporting headaches and alignment gaps
An inconsistent data foundation also turns reporting and analytics into harder and more time-consuming projects. Without uniformity across your revenue data that reflects recent updates from across different teams, you’ll have a harder time delivering reports to other teams that clearly communicate the state of play, and a harder time making credible recommendations to other teams on how to improve their performance. As a result, RevOps teams often find themselves devoting even more cycles to spinning up ad hoc, one-off reports to triage data gaps instead of building out robust, holistic reporting the entire org can use.
RevOps teams need a unified data model for their modern data stack
There’s a reason why successful RevOps teams are easing off the endless pursuit of one more point solution to bolt onto their stack. They understand that more point solutions mean more silos and ultimately more limitations in their ability to centralize their most important data. While they still need their tools to execute, smart teams are no longer relying on the Modern Data Stack. They’re adopting a unified data model that gives them these important advantages:
RevOps teams that unify their data can orchestrate a variety of mission-critical processes.
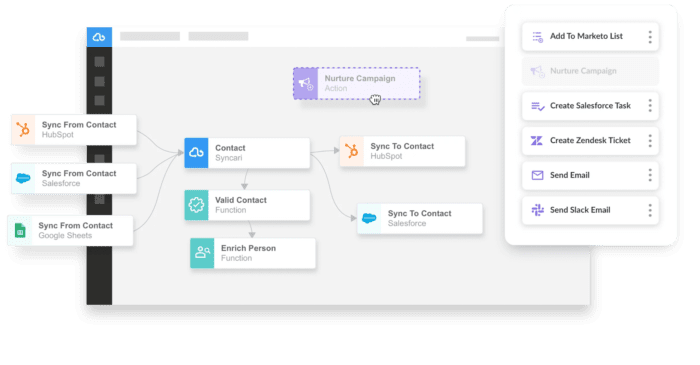
Data must be canonical
Rather than struggle with multiple versions of data trapped in different data silos, RevOps teams are now focusing on unifying their data across their different tools. By creating a canonical data model, they can rely on their data to reflect updates from every major source regularly.
Data must be shareable
When you build a canonical data model, you build a solid base from which to generate reports for your team and company leadership. When you make your data shareable, you can clearly communicate performance and resource needs to C-suite executives. You can also share credible reporting and recommendations to cross-functional teams to optimize their sales, support, and product efforts.
Data must be actionable
Having a reliable source of data that collectively encompasses the most important tools and processes within your revenue stack means you can reliably identify gaps and opportunities for improvement. Now that you know exactly where to take action, you can orchestrate processes across your tools that make improvements along the exact lines you need. Now that you know the problem with the top-of-funnel leads was a website optimization issue rather than a competitive SEO, you know where to focus your efforts next.
Data must be real time
To execute faster and collate data that is truly canonical, you need the ability to update your data in real time based on changes from all your funnel channels, updates across your tools, or updates in your internal processes. With real-time canonical data, your team is finally free of versioning and data hygiene issues that so frequently pull you sideways.
Getting started with a unified data model
There’s a reason why RevOps leaders at successful firms such as Metadata.io, Conga, and Chargebee are embracing a unified data strategy that focuses on unifying data across their tools.
Ready to get started taking control of your RevOps data?










0 Comments